
Karta graficzna PNY H100 94GB HBM3 (TCSH100NVLPCIE-PB)






- Długość karty: 268 mm
- Ilość pamięci RAM: 94 GB
- Rodzaj chipsetu: H100
- Taktowanie rdzenia w trybie boost: 1837 MHz
- Łączenie kart: Nie
- Zobacz pełną specyfikację
Skok o rząd wielkości w zakresie przyspieszonego przetwarzania danych
Wykorzystaj wyjątkową wydajność, skalowalność i bezpieczeństwo przy każdym obciążeniu dzięki procesorowi graficznemu NVIDIA H100 Tensor Core. Dzięki systemowi przełączników NVIDIA NVLink™ można podłączyć do 256 procesorów graficznych H100 w celu przyspieszenia obciążeń eksaskalowych. Procesor graficzny zawiera również dedykowany silnik transformatorowy do rozwiązywania modeli językowych o bilionach parametrów. Połączone innowacje technologiczne zastosowane w H100 mogą przyspieszyć duże modele językowe (LLM) niewiarygodnie 30-krotnie w porównaniu z poprzednią generacją, zapewniając wiodącą w branży konwersacyjną sztuczną inteligencję.

Transformacyjne szkolenie w zakresie sztucznej inteligencji
H100 jest wyposażony w rdzenie Tensor czwartej generacji i silnik transformatorowy z precyzją FP8, który zapewnia do 4 razy szybsze szkolenie w porównaniu z poprzednią generacją modeli GPT-3 (175B). Połączenie NVLink czwartej generacji, który oferuje połączenie między procesorami graficznymi o przepustowości 900 gigabajtów na sekundę (GB/s); Sieć NDR Quantum-2 InfiniBand, która przyspiesza komunikację każdego procesora graficznego w węzłach; PCIe Gen5; a oprogramowanie NVIDIA Magnum IO™ zapewnia wydajną skalowalność od systemów małych przedsiębiorstw po ogromne, zunifikowane klastry procesorów graficznych.
Wnioskowanie z głębokiego uczenia się w czasie rzeczywistym
Sztuczna inteligencja rozwiązuje szeroką gamę wyzwań biznesowych, wykorzystując równie szeroką gamę sieci neuronowych. Świetny akcelerator wnioskowania AI musi nie tylko zapewniać najwyższą wydajność, ale także wszechstronność niezbędną do przyspieszania tych sieci.
H100 poszerza wiodącą na rynku pozycję firmy NVIDIA w zakresie wnioskowania o kilka udoskonaleń, które przyspieszają wnioskowanie nawet 30-krotnie i zapewniają najniższe opóźnienia. Rdzenie Tensor czwartej generacji przyspieszają wszystkie precyzje, w tym FP64, TF32, FP32, FP16, INT8, a teraz FP8, aby zmniejszyć zużycie pamięci i zwiększyć wydajność przy jednoczesnym zachowaniu dokładności dla LLM.
Eksaskalowe obliczenia o dużej wydajności
Platforma centrum danych NVIDIA konsekwentnie zapewnia wzrost wydajności wykraczający poza prawo Moore’a. Nowe, przełomowe możliwości sztucznej inteligencji H100 jeszcze bardziej wzmacniają moc HPC+AI, aby skrócić czas dokonywania odkryć naukowcom i badaczom pracującym nad rozwiązaniem najważniejszych wyzwań świata.
H100 potraja liczbę operacji zmiennoprzecinkowych na sekundę (FLOPS) rdzeni Tensor o podwójnej precyzji, zapewniając 60 teraflopów mocy obliczeniowej FP64 dla HPC. Aplikacje HPC wykorzystujące sztuczną inteligencję mogą również wykorzystywać precyzję TF32 procesora H100 w celu osiągnięcia jednego petaflopa przepustowości w przypadku operacji mnożenia macierzy o pojedynczej precyzji, przy zerowej zmianie kodu.
H100 zawiera także nowe instrukcje DPX, które zapewniają 7-krotnie wyższą wydajność w porównaniu z A100 i 40-krotnie większe przyspieszenie w porównaniu z procesorami CPU w oparciu o algorytmy programowania dynamicznego, takie jak Smith-Waterman do dopasowywania sekwencji DNA i dopasowywania białek w celu przewidywania struktury białek.
Przyspieszona analiza danych
Analiza danych często pochłania większość czasu podczas tworzenia aplikacji AI. Ponieważ duże zbiory danych są rozproszone na wielu serwerach, skalowalne rozwiązania z dostępnymi na rynku serwerami wyposażonymi wyłącznie w procesory grzęzną w obliczu braku skalowalnej wydajności obliczeniowej.
Przyspieszone serwery z H100 zapewniają moc obliczeniową — wraz z przepustowością pamięci na poziomie 3 terabajtów na sekundę (TB/s) na procesor graficzny oraz skalowalnością za pomocą NVLink i NVSwitch™ — aby sprostać analizie danych z wysoką wydajnością i skalą w celu obsługi ogromnych zbiorów danych. W połączeniu z NVIDIA Quantum-2 InfiniBand, oprogramowaniem Magnum IO, akcelerowanym przez GPU Spark 3.0 i NVIDIA RAPIDS™, platforma centrum danych NVIDIA jest w stanie wyjątkowo przyspieszyć te ogromne obciążenia z wyższą wydajnością i efektywnością.

Wykorzystanie gotowe do zastosowania w przedsiębiorstwie
Menedżerowie IT dążą do maksymalizacji wykorzystania (zarówno szczytowego, jak i średniego) zasobów obliczeniowych w centrum danych. Często stosują dynamiczną rekonfigurację zasobów obliczeniowych, aby zapewnić odpowiednią wielkość zasobów dla używanych obciążeń.
H100 z MIG pozwala zarządcom infrastruktury standaryzować infrastrukturę akcelerowaną przez GPU, mając jednocześnie elastyczność w zakresie udostępniania zasobów GPU z większą szczegółowością, aby bezpiecznie zapewnić programistom odpowiednią ilość przyspieszonych obliczeń i zoptymalizować wykorzystanie wszystkich zasobów GPU.
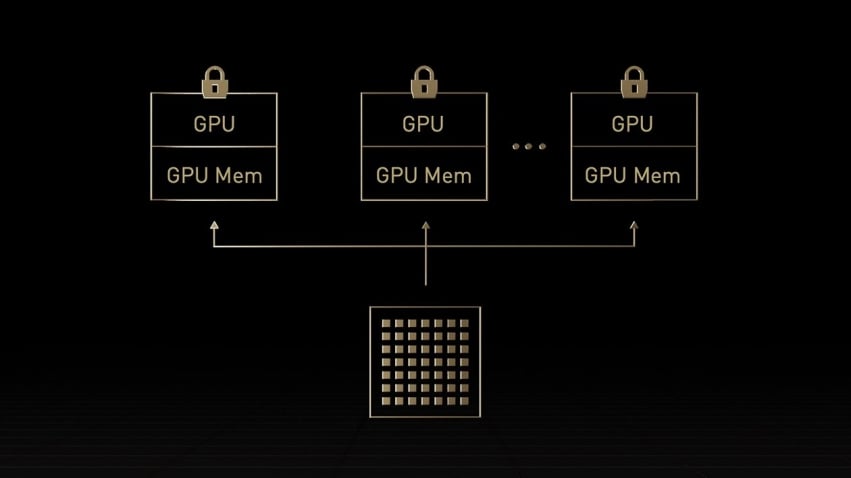
Wbudowane poufne przetwarzanie danych
Tradycyjne rozwiązania do przetwarzania poufnego opierają się na procesorze, który jest zbyt ograniczony w przypadku obciążeń wymagających dużej mocy obliczeniowej, takich jak sztuczna inteligencja na dużą skalę. NVIDIA Confidential Computing to wbudowana funkcja zabezpieczeń architektury NVIDIA Hopper™, dzięki której H100 stał się pierwszym na świecie akceleratorem oferującym takie możliwości. Dzięki NVIDIA Blackwell możliwość wykładniczego zwiększenia wydajności przy jednoczesnej ochronie poufności i integralności używanych danych i aplikacji umożliwia odblokowanie wglądu w dane jak nigdy dotąd. Klienci mogą teraz korzystać ze sprzętowego zaufanego środowiska wykonawczego (TEE), które w najbardziej wydajny sposób zabezpiecza i izoluje całe obciążenie.
Wyjątkowa wydajność dla wielkoskalowej sztucznej inteligencji i HPC
Procesor graficzny Hopper Tensor Core będzie zasilał architekturę NVIDIA Grace Hopper CPU+GPU, stworzoną specjalnie do obliczeń z akceleracją w skali terabajtów i zapewniającą 10-krotnie wyższą wydajność w dużych modelach AI i HPC. Procesor NVIDIA Grace wykorzystuje elastyczność architektury Arm®, aby stworzyć architekturę procesora i serwera zaprojektowaną od podstaw z myślą o przyspieszonym przetwarzaniu. Procesor graficzny Hopper jest połączony z procesorem Grace za pomocą ultraszybkiego połączenia międzyukładowego firmy NVIDIA, zapewniając przepustowość 900 GB/s, 7 razy szybciej niż PCIe Gen5. Ta innowacyjna konstrukcja zapewni do 30 razy większą łączną przepustowość pamięci systemowej dla procesora graficznego w porównaniu z najszybszymi dzisiejszymi serwerami i do 10 razy wyższą wydajność w przypadku aplikacji obsługujących terabajty danych.

- Długość karty 268 mm
- Ilość pamięci RAM 94 GB
- Rodzaj chipsetu H100
- Taktowanie rdzenia w trybie boost 1837 MHz
- Łączenie kart Nie
Morele MAX to gwarancja darmowej dostawy od , możliwości zwrotu zakupów nawet do 30 dni oraz bezpłatnego zwrotu do Paczkomatów 24/7 i Punktów DPD Pickup.
Aktywuj pakiet już dzisiaj i zacznij oszczędzać!
Sprawdź, co zyskasz dla tego zakupu
Karta graficzna PNY H100 94GB HBM3 (TCSH100NVLPCIE-PB) możemy dostarczyć do Ciebie już jutro! Jeśli chcesz poznać dokładny czas dostawy, wprowadź kod pocztowy lub nazwę miejscowości.
Przepraszamy, czat na żywo w tej chwili jest już nieczynny. Jeśli masz jakieś pytanie lub problem, napisz do nas wiadomość lub odwiedź nasze centrum pomocy.
Czat na żywo jest do Twojej dyspozycji codziennie w godzinach:
poniedziałek-piątek: 9:00-17:00